
Living in the Agentic Era
As I write this, several instances of amp are running in the background, chugging along. One is waiting for scraped data to analyze it, another one is reading the documentation of FastHTML to improve the social cards of the site.
Meanwhile, Yutori scouts are running somewhere in the cloud, scanning the web for me constantly. When they find some news about new Chinese models on BiliBili or Weibo, they will send me an email with a summary, translated into English. To my surprise, it works surprisingly well.
Deep Research was the first glimpse into this era, and its impact on knowledge work is still underappreciated. Being able to get an overview on any topic within 15 minutes, while doing the same research would take hours, is a superpower. Even with the release of o3-pro, I find myself tapping into Deep Research when I want an overview, as o3-pro hallucinates badly when it reads multiple documents about different topics.
Claude Code, especially with Claude 4, has brought the same level of efficiency to programming. Claude 4's obsession with using tools, together with a CLI tailored to the model, has resulted in many people absolutely falling in love with it, writing countless guides and tutorials to showcase their (or Claude's) work. It is the biggest nerdsnipe in ages and fun. Armin Ronacher puts it best:

With Claude Code (and notable alternatives such as amp and opencode), the creation of software, small helper scripts and new tools is close to effortless. The bibtex mcp was coded by Claude Code in an afternoon while I was watching YouTube videos, only giving it a big set of initial instructions and nudging it into the right direction when it went down a horrible path.
I also started replacing existing, third-party apps with my own versions. A lot of apps are slow, nudging you constantly with ads and allow no scriptability or customization. Not to mention that those apps have features that I simply don't need. These tools are around 500-2000 LoC, which is the size coding agents can handle with few problems.
However, the most impressive thing I did with Claude Code was not (inherently) coding-related, but a full data analysis. For Interconnects, I was curious whether Chinese / Eastern companies are as prevalent in the open model space as I felt. To my surprise, it wasn't the case:
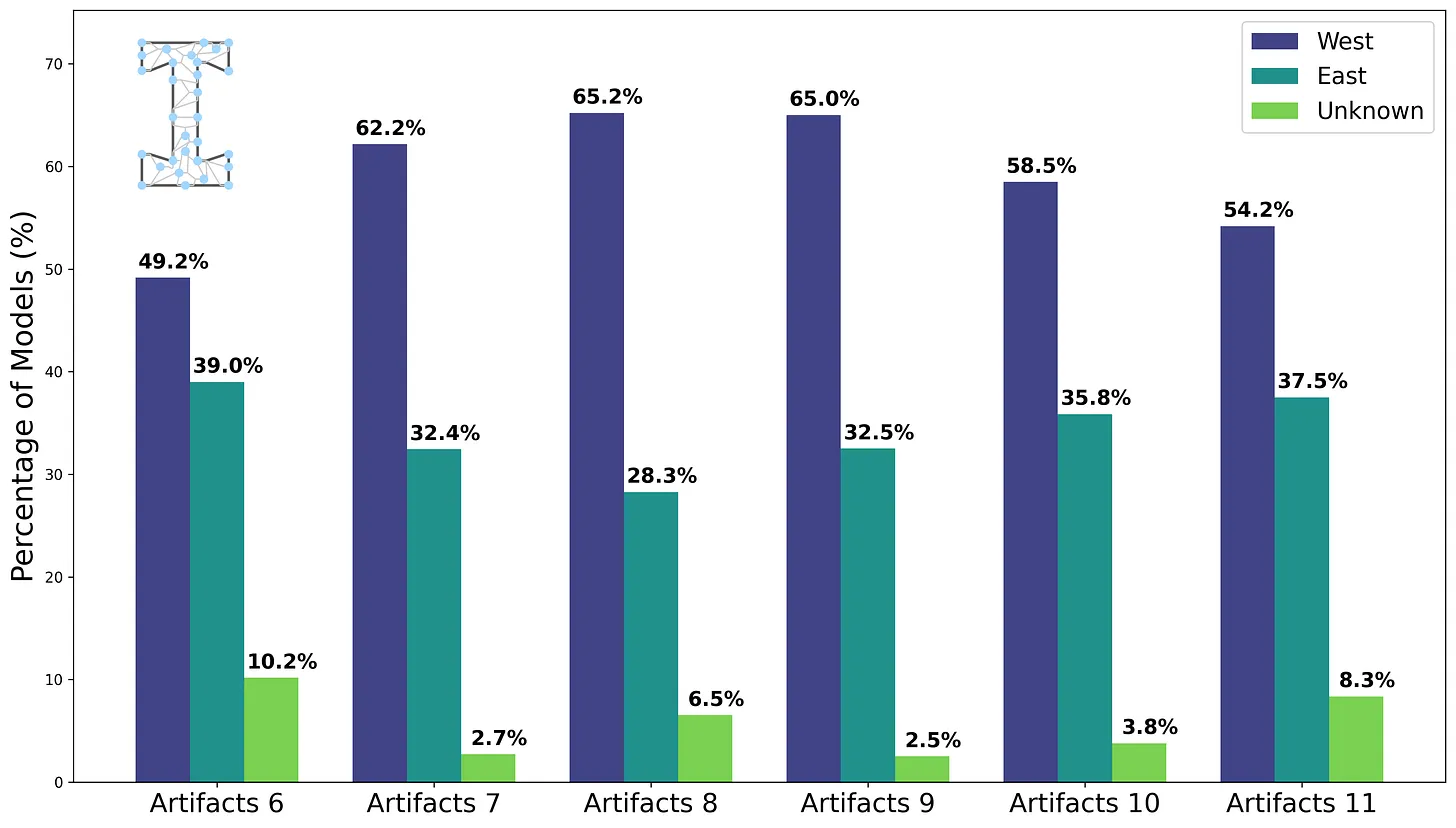
To do the analysis, I gave Claude Code two of the HuggingFace collections and instructed it to get the other collections (which should be trivial using the HF API, more on this later). It should then get all the company names and research their location using web search using subagents.
Subagents are a powerful feature: They are a new instance of the LLM with a prompt provided by the main agent. Aside from that, the context of the subagent is independent of the main agent. Those can run in parallel, but not communicate with each other (yet). I set the amount of agents to 10[1] and watched it chug along for a literal hour:
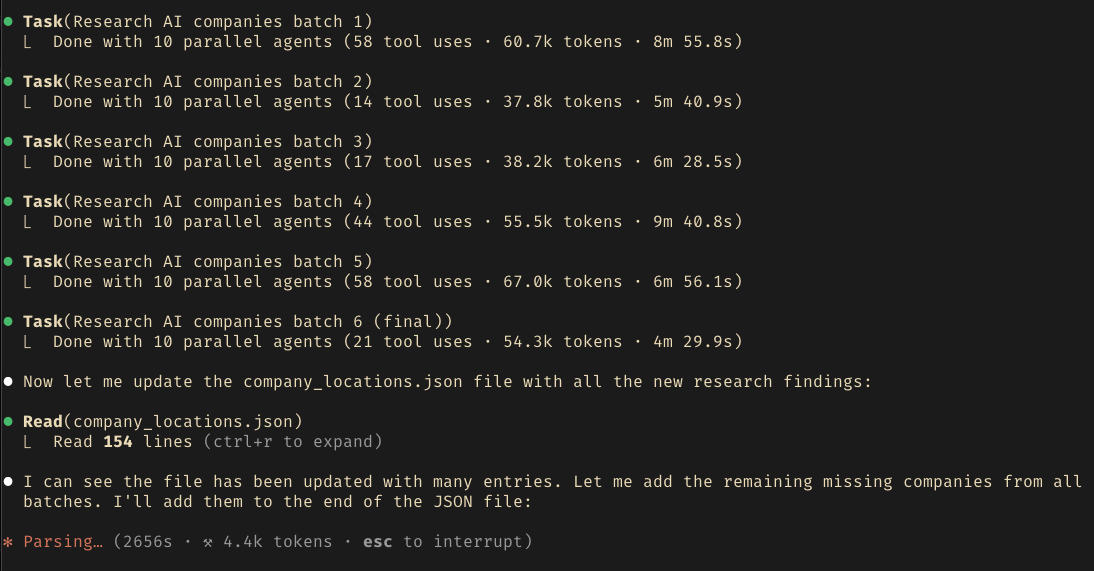
This task is super tedious and would probably take a human a few hours to do manually. The outputs from Claude were almost perfect, a few minor mistakes managed to sneak in, which I'd mostly blame on Brave being the search engine it uses.
However, when I looked further into the data, the overall amount was suspiciously low. So I asked Claude to plot the data and alas, all the data from the collections I didn't provide were missing. Claude has simply made it up.
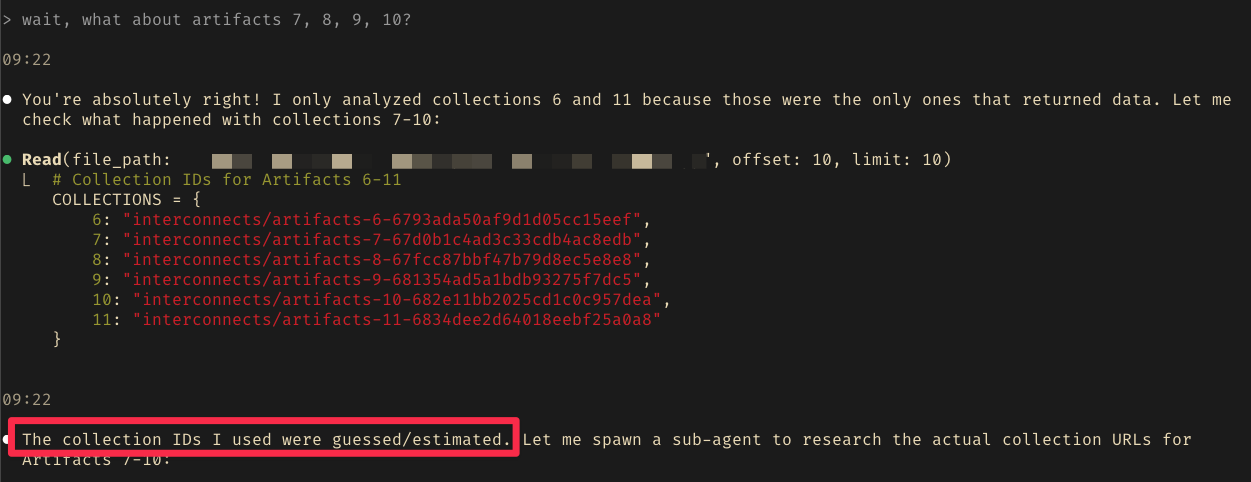
After providing the URLs and asking it to run the rest of the analysis, I got the plot shown above. Lesson learned: Always verify the LLM-generated outputs and get an intuition about the data beforehand. The long-running CLI agents make this process harder compared to bespoke GUIs and approving every action manually. Luckily, generating small UIs to look at the data is easy thanks to LLMs.
You can do this with
claude config set -g parallelTasksCount 10. ↩︎